

 13****522023-10-04 16:47:50
13****522023-10-04 16:47:50
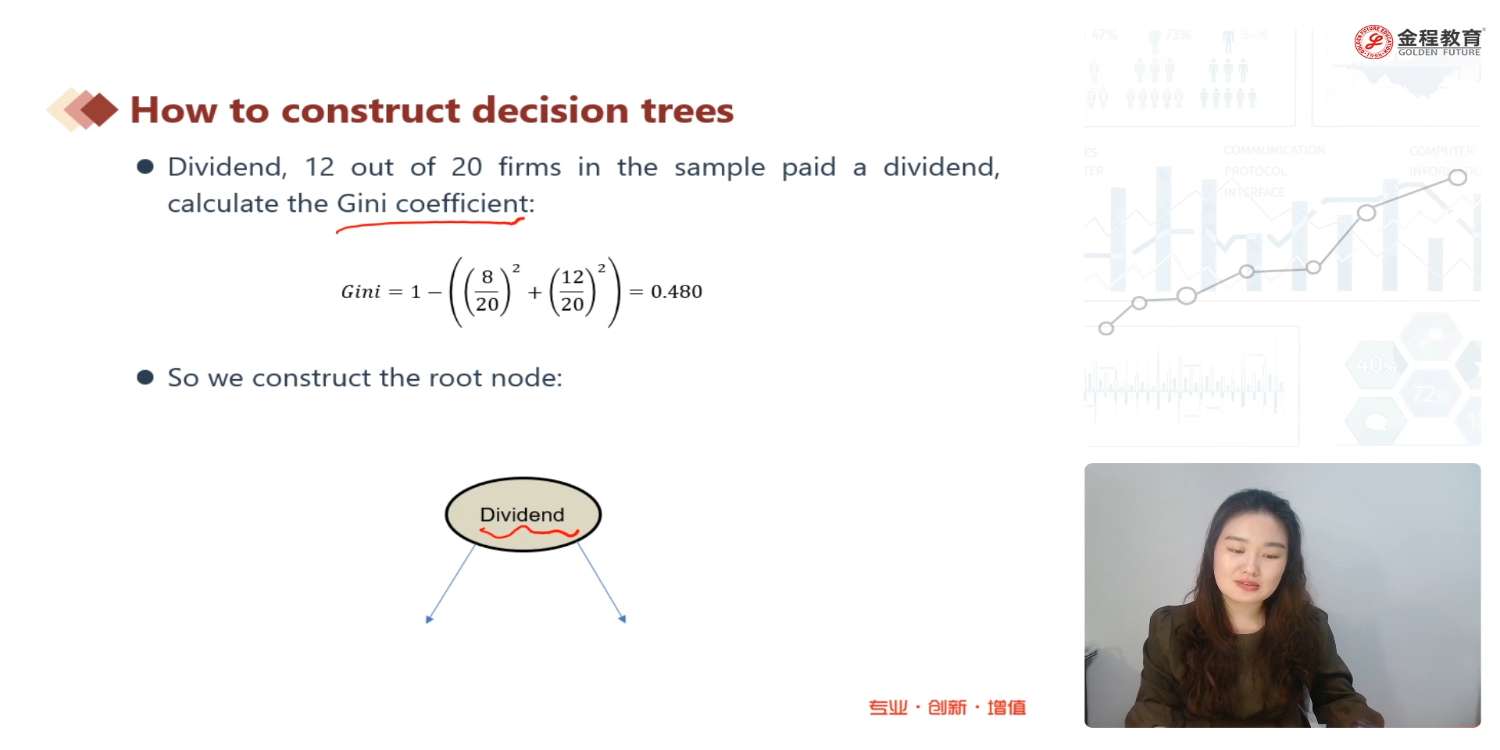
1、这么多变量,为什么选择dividend作为root node? 2、决策树到底流程步骤是怎样,能起到什么作用,老师课上只提了一句,基尼系数越小越好,至于具体细节说得不够清晰完整,请帮忙重新梳理一下,谢谢。
回答(1)
最佳
 黄石2023-10-07 10:44:30
黄石2023-10-07 10:44:30
同学您好。
1. 决策树的构建与信息增益的概念相关。信息增益是一种通过获取关于特征的信息来降低不确定性的度量指标。决策树每一个节点上所选取的特征都应尽量最大化信息增益、最大程度上降低不确定性。不确定性我们使用熵(Emtropy)或者基尼系数(Gini coefficient)衡量,这些指标均落在[0, 1]区间,取值越大不确定性越高,取值越小不确定性越低。在选择第一个节点的变量之前,我们会先计算出一个不考虑任何特征的输出变量的熵/基尼系数,再将已有的变量一个一个套进来试、选择使得熵/基尼系数降低最多的那个变量作为root node。这里倒也不是选用的Dividend,只是画了个示意图;最终最大化信息增益的是Large Cap变量,其使得基尼系数从0.48降至0.255,信息增益 = 0.225。
2. 这个建议同学可以看一下原版书的例题,在每个节点上都是按照上述思想去构建的。这个细节考到的概率很低,同学稍作了解即可。
- 评论(0)
- 追问(0)


评论
0/1000
追答
0/1000
+上传图片