

 173****63662022-09-19 14:35:50
173****63662022-09-19 14:35:50
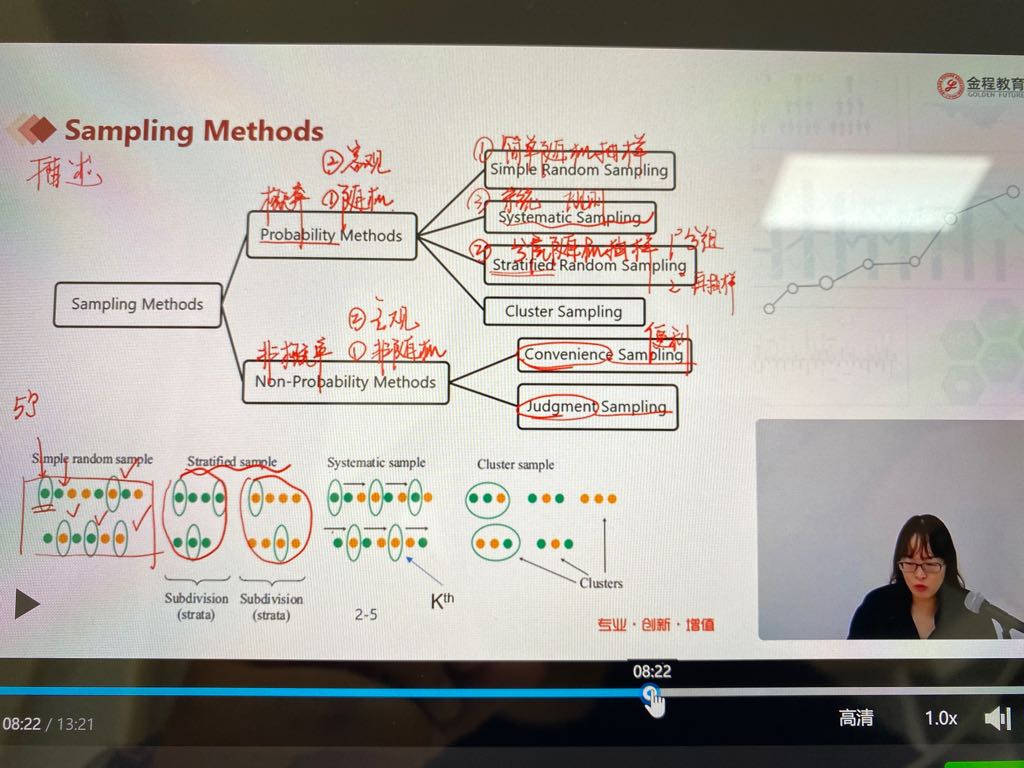
老师的讲解比较粗略易混淆,比如文字描述中,系统抽样重点是Kth,是间隔等距离抽样的意思吗?而分层抽样还要注意同比例抽样吗?按一定规则抽样同样存在于这几个吧?希望再举例详细说明下区别便于理解记忆。


回答(1)
 Evian, CFA2022-09-19 17:58:23
Evian, CFA2022-09-19 17:58:23
ヾ(◍°∇°◍)ノ゙你好同学,
系统抽样重点是Kth,是间隔等距离抽样的意思吗
【回复】嗯嗯,是的
分层抽样还要注意同比例抽样吗?
【回复】嗯嗯,是同比例,Stratifed Random Sampling分层随机抽样
例如:全球的人类是总体,然后
1.按照每个国家分组,形成的subpopulations是每一个国家的人类
2.在每个subpopulations中,抽样,抽出的样本数量是按照比例抽的,例如中国人站全球人的20%,那么样本中中国人也要占20%
3.将每个国家抽出来的数据组成样本
按一定规则抽样同样存在于这几个吧?希望再举例详细说明下区别便于理解记忆
【回复】
cluster sampling:
1.在总体中分组,形成clusters
2.随机抽样其中clusters
3.直接使用抽到的clusters
例如:全球的人类是总体,然后
1.按照每个国家分组,形成的cluster就是每一个国家的人类
2.随机抽国家,假设抽出来了中国和巴基斯坦
3.直接用这两个国家的人类作为样本
convenience sampling,便利抽样,说白了就是“怎么方便怎么来抽样”,题目如附图
judgmental sampling,研究的人主观决定去抽什么,决定样本,例如审计师会决定某个部门的抽样数据较多(因为师财务报表粉饰出问题概率较大内容对应的部门)
----------------------
学而时习之,不亦说乎👍【点赞】鼓励自己更加优秀,您的声音是我们前进的源动力,祝您生活与学习愉快!~


- 评论(0)
- 追问(4)
- 追问
-
cluaster抽样就是分层抽样的第一步?分层抽样第二步是按比例抽样。
- 追答
-
不是的,不是“谁是谁的第一步”,分成抽样和聚类抽样有共同点和区别点(以下这个例子比上述的例子更优)
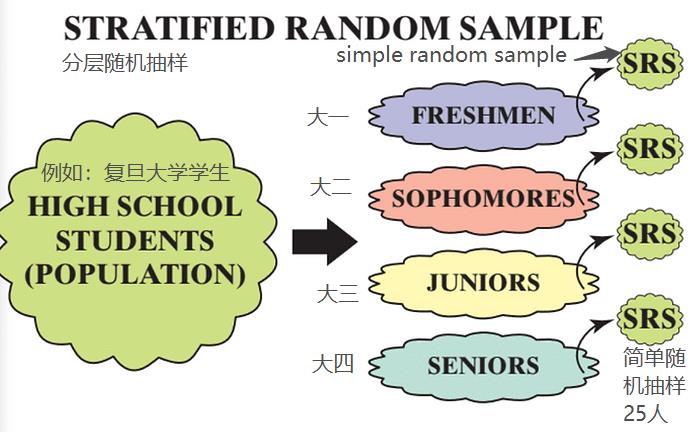
分层随机抽样
例如,假设我们想了解复旦大学的学生是否支持新建停车场。可能存在的问题的新生的支持程度将不同于高年级的学生。在这种情况下,我们希望获得样本数据(假设n=100)涵盖所有大学四个年级。分层随机样本的步骤如下:
1
以学校所有复旦学生为总体,按年级将他们分成不同的subpopulation(阶层)。在每个阶层中,学生都是相似的属性(同一年级)。
2
每个阶层随机抽25名学生,一共100名学生。
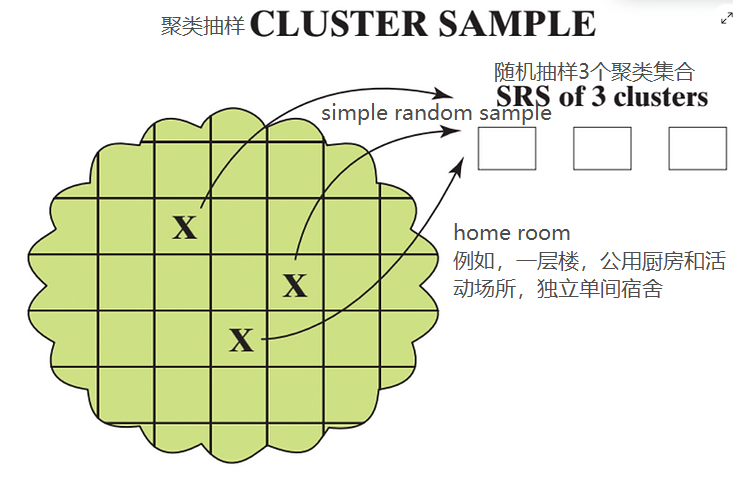
聚类抽样
分层随机抽样在学校里寻找100名不同的学生可能相当耗时。于是我们可以使用集群抽样。在聚类抽样时,需要保证每个集群都能很好地代表总体,这一点很重要。在复旦学校中,这意味着每个cluster聚类集合必须良好代表性总体(四个年级全部学生),我们可以找(home room,类似大学宿舍,不是按年级和专业分,而是随机入住的大学宿舍),在每个home room都会有四个年级的学生。以下是集群示例的步骤:
1
以复旦大学所有学生作为总体,按home room将总体分成聚类集合。在每个聚类集合中,学生都是不同的(多个年级)。
2
随机取3个聚类集合作为样本数据。
这两种抽样方法有什么相同之处?
1
这两种抽样方法都是对总体进行分组。
2
这两种采样方法都使用了简单随机抽样的概念。
这两种抽样方法有什么不同?
1
分层随机样本每阶层的属性一致(同一年级,不能代表总体),聚类抽样每隔聚类集合属性不一致(四个年级都有,可以代表总体)。
2
对于分层抽样,从每阶层中抽取一定数量样本,从而汇总得到总样本。对于聚类抽样,随机抽几个聚类集合。
参考信息:
https://www.statsmedic.com/post/stratified-random-sample-vs-cluster-sample
- 追问
-
全球人口按国家分组,每组按比例随机抽样就是分层随机抽样。全球人口按种族分组,每组包含不同国家人口,没有遍历只随机抽样部分组别,就是聚类抽样?全体学生按宿舍分组,和按年级分组都是分组的方法不同而已,本质没有区别吧?唯一区别就是分层要遍历各组,还要按比例抽样,而聚类不一定,对吗?
- 追答
-
嗯嗯,是的~
你理解的很到位~


评论
0/1000
追答
0/1000
+上传图片